理解并实现 GPT-1、GPT-2 和 GPT-3 架构
 admin 2025-05-19
184
admin 2025-05-19
184
大型语言模型(LLM),例如ChatGPT、Gemini、Claude等,已经存在了一段时间,我相信我们所有人都已经使用过其中至少一个。在撰写本文时,ChatGPT已经实现了基于GPT的模型的第四代,名为GPT-4。但是你知道GPT到底是什么,底层神经网络架构是什么样的吗?在本文中,我们将讨论GPT模型,特别是GPT-1、GPT-2和GPT-3。我还将演示如何使用PyTorch从头开始编写它们,以便您更好地了解这些模型的结构。
GPT简史在讲解GPT之前,我们先来了解一下Transformer的原始架构。一般来说,Transformer主要由两个部分组成:编码器(Encoder)和解码器(Decoder)。前者负责理解输入序列,而后者则用于根据输入生成另一个序列。例如,在问答任务中,解码器会对输入序列产生答案,而在机器翻译任务中,解码器则用于生成输入的翻译。
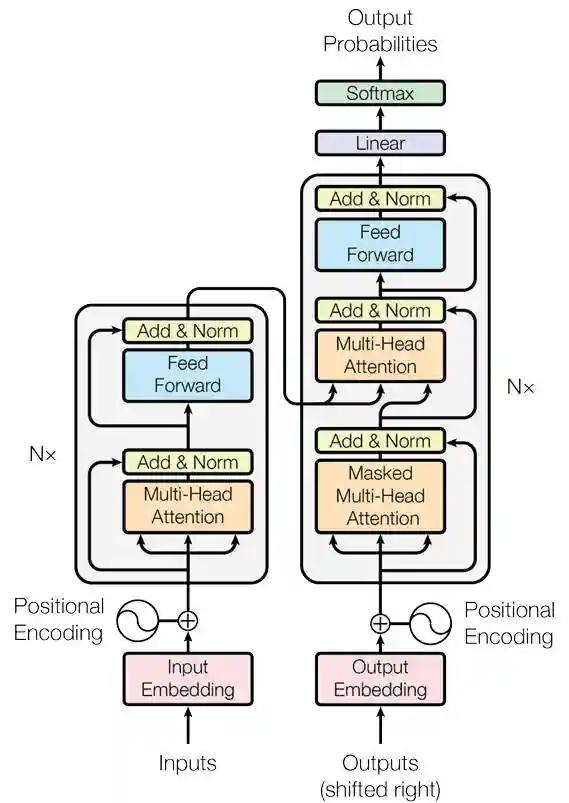
图1.Transformer模型。左侧的块为编码器,右侧的块为解码器[1]。
上面提到的Transformer的两个主要组件还包含几个子组件,例如注意力模块、前瞻掩码和层规范化。在这里我假设你已经对它们有了基本的了解。
事实证明,Transformer在语言建模方面具有令人印象深刻的性能。有趣的是,未来的研究人员发现它的编码器和解码器部分可以单独工作。这实际上是BERT(Transformer的双向编码器表示)和GPT(生成式预训练Transformer)被发明的时刻,其中BERT基本上只是一堆编码器,而GPT是一堆解码器。
更具体地说,GPT的第一个版本(GPT-1)是由OpenAI于2018年发布的。随后,GPT-2和GPT-3分别于2019年和2020年发布。然而,当时知道GPT的人并不多,因为它只能通过API使用。直到2022年,OpenAI才发布了带有后端的ChatGPT,让公众可以轻松地与这个LLM进行交互。下图显示了GPT模型的演变。

图2.GPT模型随时间的演变
GPT-1第一个GPT版本发表在2018年Radford等人的一篇题为“通过生成式预训练提高语言理解”的研究论文中。之前我提到过,GPT基本上只是一堆解码器,在GPT-1的情况下,解码器块重复了12次。重要的是要记住,GPT-1中实现的解码器架构与原始Transformer中的架构并不完全相同。在下图中,左侧的模型是GPT-1论文中提出的解码器,而右侧的模型是原始Transformer的解码器部分。在这里我们可以看到原始解码器中以红色突出显示的部分在GPT-1中并不存在。这主要是因为这个组件用于组合来自编码器和解码器输入本身的信息。在GPT-1的情况下,由于我们没有编码器部分,因此我们可以省略它。
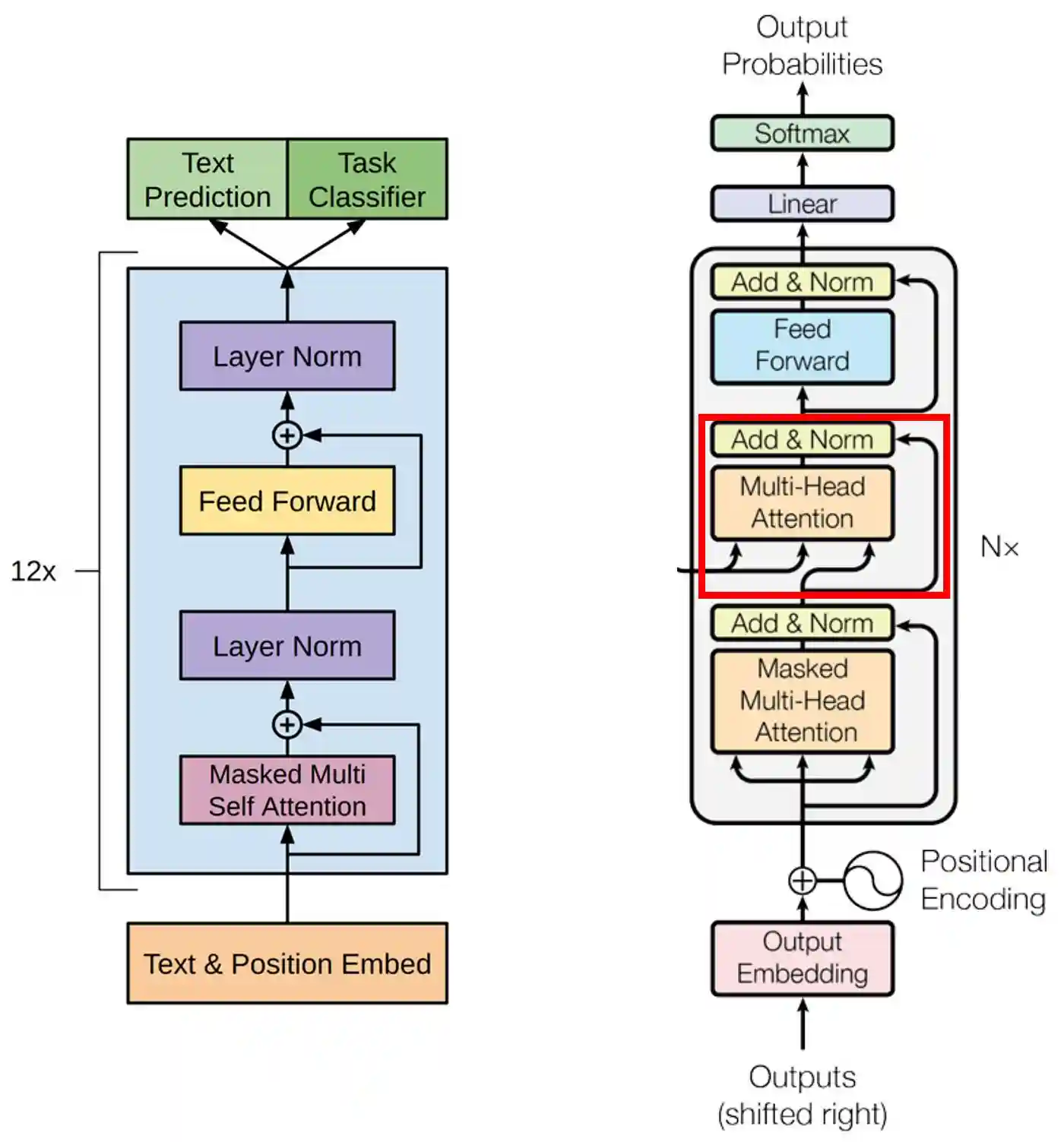
图3.GPT-1架构(左)和原始Transformer架构的解码器部分。
GPT-1预训练GPT-1模型的训练过程分为两个步骤:预训练和微调。预训练的目标是教会模型根据前面的token预测序列中的下一个token——这个过程通常被称为语言建模。这个预训练步骤使用自监督机制,即标签来自数据集本身的训练过程。通过这种方法,我们不需要进行人工标记。相反,我们可以从长文本中随机位置分块513个token,将前512个设置为特征,最后一个设置为标签。这个token数量是根据GPT-1的上下文窗口参数选择的,默认情况下设置为512。除了token化机制之外,GPT-1还使用BPE(字节对编码)。这本质上意味着每个token不一定对应一个单词。相反,它也可以是一个子词,甚至是一个单独的字母。
GPT-2预训练是使用下图4所示的目标函数完成的,其中uᵢ是被预测的标记,uᵢ₋ₖ,,uᵢ₋₁是k个前标记(上下文窗口),Θ是模型参数。这个等式本质上是在给定序列中的前一个标记的情况下计算一个标记出现的可能性。概率最高的标记将作为预测输出返回。通过迭代执行此过程,模型将继续提示中提供的文本。如果我们回到图3,我们将看到GPT-1模型有两个头:文本预测和任务分类器。稍后,这个文本生成过程将使用文本预测头来完成。
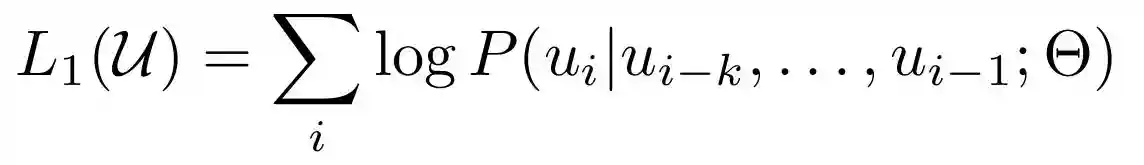
图4.预训练的目标函数
GPT-1微调尽管默认情况下GPT是一个生成模型,但在微调阶段我们将其视为判别模型。这主要是因为在这个阶段,目标只是执行一个典型的分类任务。在下面的目标函数中,y表示要预测的类,而x¹,,xᵐ表示序列x中的m个输入标记。我们可以简单地将这个等式想象成我们想要将文本归类到特定的类别中。这种分类机制稍后将用于执行各种下游任务,我很快就会解释。
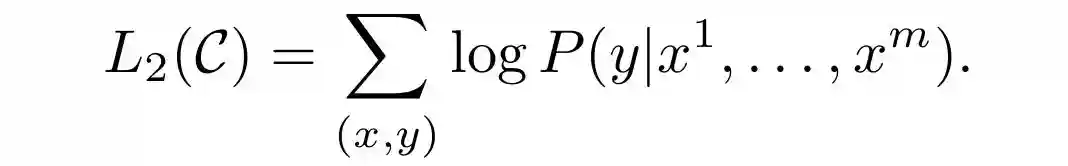
图5.下游分类任务的目标函数
论文中实验了四种不同的下游任务:分类、自然语言推理(蕴涵)、句子相似度和多项选择题回答。下图说明了这些任务的工作流程。
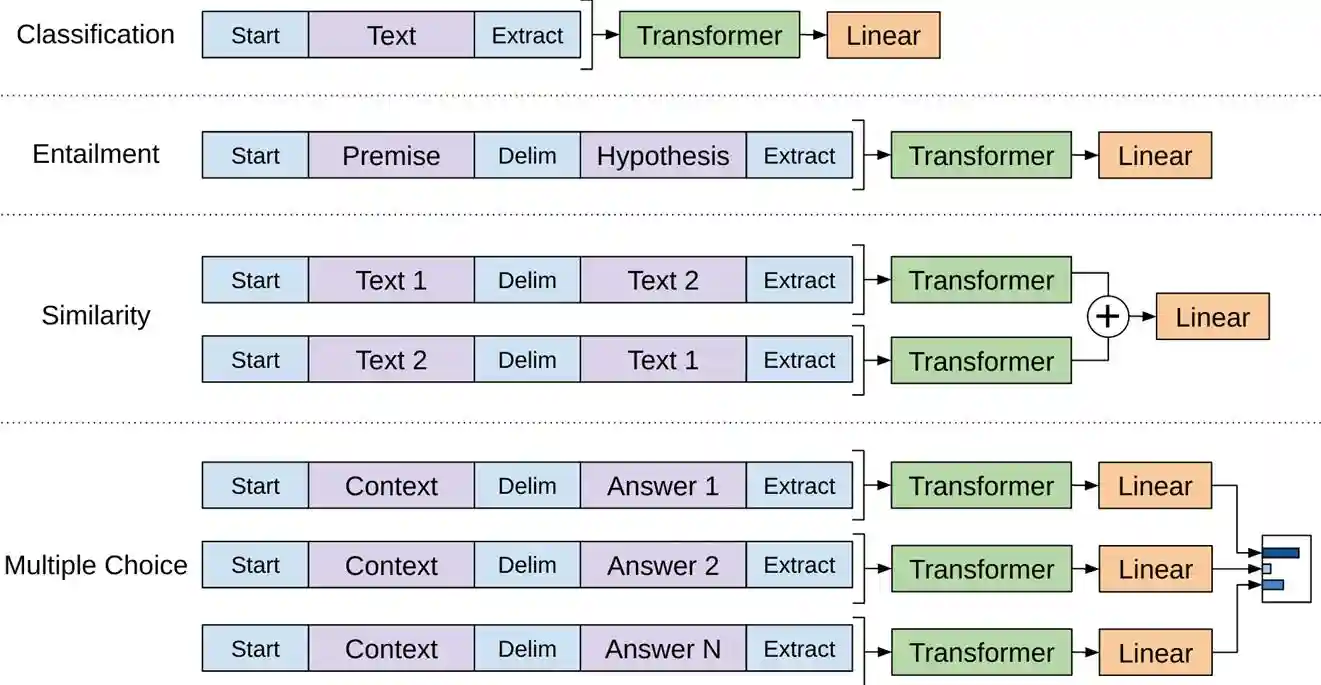
图6.GPT-1模型的下游任务工作流程
绿色的Transformer块是GPT-1模型,每个模型都具有完全相同的架构。为了让模型能够执行不同的任务,我们需要相应地排列输入文本。对于标准文本分类任务(例如情绪分析或文档分类),我们可以简单地将标记序列放在开始和提取标记之间,以标记文本的开始和结束,然后再将其输入到GPT-1模型中。然后将生成的张量转发到线性层,该层中的每个神经元对应一个类。

图7.情感分析(分类)任务的输入文本示例和相应标签
对于文本蕴涵,模型将前提和假设作为一个序列接受,并用分隔符标记分隔。在这种情况下,任务分类器头负责分类假设是否蕴涵前提。

图7.情感分析(分类)任务的输入文本示例和相应标签
在文本相似性任务中,该模型的工作原理是接受两个文本,以两种不同的顺序进行比较:文本1后跟文本2,文本2后跟文本1。这两个序列并行输入到GPT模型中,然后将得到的输出相加,最终预测它们是否相似。或者,我们也可以配置输出层来执行回归任务,返回连续的相似度分数。

图9.文本相似度测量数据集示例
最后,对于多项选择题,我们将包含事实的文本和相应的问题都包装在上下文块内。接下来,我们在将其中一个答案附加到分隔符标记之前放置一个分隔符标记。我们对每个问题的所有可能答案都执行相同的操作。使用此数据集结构,我们通过将它们传递到模型中进行推理,让它计算每个问答对之间的相似度得分。该分数表示每个答案根据给定事实解决问题的程度。我们基本上可以将其视为标准分类任务,其中选定的答案是具有最高相似度得分的答案。

图10.多项选择题回答任务的数据集示例
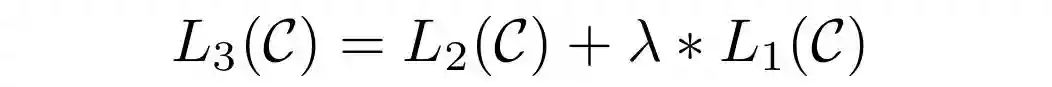
图11.用于微调的目标函数
因此,总而言之,GPT-1的要点是,它基本上是通过继续前面的序列来工作的。如果我们不进一步微调模型,它将根据对自监督训练阶段提供的数据的理解继续该序列。同时,如果我们进行微调,模型也将继续该序列,但仅使用监督学习阶段提供的特定基本事实。
GPT-1实现:前瞻掩码和位置编码既然我们已经了解了GPT-1背后的理论,现在让我们从头开始实现架构设计!我们将从导入所需的模块开始。
(1)的行中Codeblock2BATCH_SIZE=1(2)SEQ_LENGTH=512(4)D_MODEL=768(6)NUM_HEADS=12(8)DROP_PROB=0.1(3))是表示上下文窗口的另一个术语,设置为512。在训练数据集上执行的BPE标记化机制会产生40,000个唯一标记,因此我们需要将此数字用于VOCAB_SIZE((5))。之前我提到解码器层重复了12次。在上面的代码中,这个数字分配给变量N_LAYERS()。每个解码器层本身都包含一些其他组件,这些组件的参数也需要手动配置。这些参数是注意力头(7)(9)由于已配置了所需的参数,接下来要做的是初始化一个用于创建所谓的前瞻掩码的函数和一个用于创建位置嵌入的类。前瞻掩码可以被认为是一种工具,它可以防止模型在训练阶段查看后续标记,因为在推理阶段的后期,后续标记不可用。同时,位置嵌入用于用特定数字标记每个标记,这对于保留有关标记顺序的信息很有用。事实上,尽管前瞻掩码已经包含了这些信息,但位置嵌入进一步强调了这一点。
请查看下面的代码块3和4,了解我如何实现刚刚解释的两个概念。
Codeblock4classPositionalEncoding():defforward(self):pos=(SEQ_LENGTH).reshape(SEQ_LENGTH,1)i=(0,D_MODEL,2)denominator=(10000,i/D_MODEL)even_pos_embed=(pos/denominator)odd_pos_embed=(pos/denominator)stacked=([even_pos_embed,odd_pos_embed],dim=2)pos_embed=(stacked,start_dim=1,_dim=2)returnpos_embedGPT-1实现:解码器现在让我们谈谈我在DecoderGPT1()类内部实现的解码器部分。我这样命名的原因是因为我们将专门将其用于GPT-1。请参阅Codeblock5a和5b中的详细实现。
(1)num_heads=NUM_HEADS,batch_first=True)(3)_forward=((D_MODEL,HIDDEN_DIM),(5)_(_forward[0].weight,0,0.02)(7)我在上述方法中初始化了几个神经网络层__init__(),其中每个层都对应于图3中所示的解码器内的每个子组件。第一个是多头注意层(),其中和(2)D_MODEL(5)
对于前馈()块,我使用()创建它(6)和的代码手动配置它们(1))。第一个输入是嵌入的标记序列,而第二个输入是我们之前定义的函数生成的前瞻create_mask()掩码。
(1)residual=x(3)print(f"afterattention\t\t:{}")x=_0(x)(5)print(f"afteraddition\t\t:{}")x=_0(x)(7)print(f"afterfeedforward\t:{}")x=_1(x)print(f"afterdropout\t\t:{}")x=x+residualprint(f"afteraddition\t\t:{}")x=_1(x)print(f"afternormalization\t:{}")returnx在执行任何操作之前,我们在上述方法中做的第一件事forward()是将原始输入张量存储x到residual变量((3)xattn_maskx(5)(7)
为了检查我们的解码器是否正常工作,我们可以传递一个大小为1×512×768的张量,如下面的代码块6所示。这模拟了一个512个标记的序列,每个标记都表示为一个768维向量。
Codeblock6outputoriginalresidual:([1,512,768])afterattention:([1,512,768])afterdropout:([1,512,768])afteraddition:([1,512,768])afternormalization:([1,512,768])xresidual:([1,512,768])afterfeedforward:([1,512,768])afterdropout:([1,512,768])afteraddition:([1,512,768])afternormalization:([1,512,768])GPT-1实现:带输入和文本预测的解码器由于我们已经完成了解码器块,我们现在将连接它之前的输入层,并将文本预测头附加到输出。你可以在GPT1()下面的类中看到我是如何实现它们的。
(1)_encoding=PositionalEncoding()(3)=(in_features=D_MODEL,out_features=VOCAB_SIZE)(5)_(,mean=0,std=0.02)(1))。其次,我们使用之前创建的PositionalEncoding()类初始化位置编码张量((3))。接下来,我们初始化一个线性层,它基本上对应于文本预测头((5)和(1))。接下来,我们通过逐元素加法将位置编码张量注入到x中((3)行所示。请记住,GPT-1模型有两个头。在这种情况下,文本预测头将包含在forward()方法内,而任务分类器头稍后将在单独的类中实现。为了实现这一点,我将返回原始解码器输出(decoder_output)以及下一个单词预测输出(text_output),如第Codeblock7bdefforward(self,x):print(f"originalinput\t\t:{}")x=_embedding(())(2)print(f"afteraddition\t\t:{}")fori,decoderinenumerate():x=decoder(x,attn_mask=look_ahead_mask){i}\t:{}")decoder_output=x(5)我们可以检查我们的GPT1()类是否与下面的Codeblock8正常工作。这里的x张量假设为长度为SEQ_LENGTH(512)的令牌序列,其中每个元素都是0到VOCAB_SIZE(40,000)范围内的随机整数,代表编码后的令牌。
Codeblock8outputoriginalinput:([1,512])(2)afteraddition:([1,512,768])afterdecoder1:([1,512,768])afterdecoder3:([1,512,768])afterdecoder5:([1,512,768])afterdecoder7:([1,512,768])afterdecoder9:([1,512,768])afterdecoder11:([1,512,768])decoder_output:([1,512,768])(4)根据上面的输出,我们可以看到_embedding层成功地将512个标记的序列((2))。这个张量维度一直保持不变,直到最后一个解码器层,然后将输出存储在decoder_output变量中((4)),包含有关下一个令牌预测的信息。—在原始Transformer中,这通常称为右移输出。它基本上意味着第0行中存储的信息是第一个标记的预测,第一行包含第二个标记的预测,依此类推。因此,由于我们想要预测第513个标记,因此我们可以简单地取出最后(第512)行并选择与概率最高的标记对应的元素。
要计算模型参数的数量,我们可以使用count_parameters()下面的函数。
Codeblock9output146534464GPT-1实现:任务分类器头请记住,我们的GPT1()类仅包含文本预测头。仅对于语言建模而言,这已经足够了,但对于微调,我们需要手动创建任务分类器头。查看下面的Codeblock10以了解我如何实现它。
(1)_(,mean=0,std=0.02)defforward(self,x):(1))。稍后,解码器的输出将用作forward()方法的输入(Codeblock11task_classifier=TaskClassifier()x=(BATCH_SIZE,SEQ_LENGTH,D_MODEL)x=task_classifier(x)(1)如果我们仔细观察上面的输出,我们可以看到生成的张量现在具有1×512×3的形状((1))。然后,我们使用解码器的输出作为任务分类器头的输入,它将返回可用类的逻辑(Codeblock12defgpt1_fine_tune(x,gpt1,task_classifier):print(f"originalinput\t\t:{}")decoder_output,text_output=gpt1(x)(2)print(f"class_output\t\t:{class_}")returntext_output,class_output
根据以下代码块产生的输出,我们可以看到上述gpt1_fine_tune()函数正常运行。
Codeblock13outputoriginalinput:([1,512])decoder_output:([1,512,768])text_output:([1,512,40000])class_output:([1,512,3])GPT-1的局限性
尽管在处理图6中展示的四个下游任务时取得了显著的成果,但重要的是要知道这种方法也有一些缺点。首先,训练过程很复杂,因为我们需要在单独的过程中进行预训练和微调。其次,由于微调是一个判别过程,我们仍然需要进行手动标记(与使用自监督标记方法的预训练生成过程不同)。第三,该模型不够灵活,因为它只能处理经过微调的任务。例如,专门用于情绪分析的模型不能用于问答任务。——幸运的是,不久之后就推出了GPT-2来解决这些问题。
GPT-2GPT-2是在GPT-1发布几个月后发表的一篇题为《语言模型是无监督的多任务学习者》的论文中引入的。这篇论文的作者发现,纯粹的GPT语言模型其实不需要微调就能完成各种下游任务,通过修改目标函数就可以实现这一点。如果说GPT-1仅仅根据前一个token序列进行预测,即P(output|input),那么GPT-2则不仅根据该序列进行预测,还会根据给定的任务进行预测,即P(output|input,task)。有了这个性质,每当给定的任务不同时,同样的提示就会导致模型产生不同的输出。而且有趣的是,我们可以简单地将任务作为自然语言包含在提示中。
例如,如果你用“loremipsumdolorsitamet”提示模型,它很可能会继续使用“consecteturadipiscingelit”。但如果你在提示中包含“这是什么意思?”这样的任务,模型就会解释它到底是什么。我在ChatGPT中尝试过这个,答案正是我所期望的。
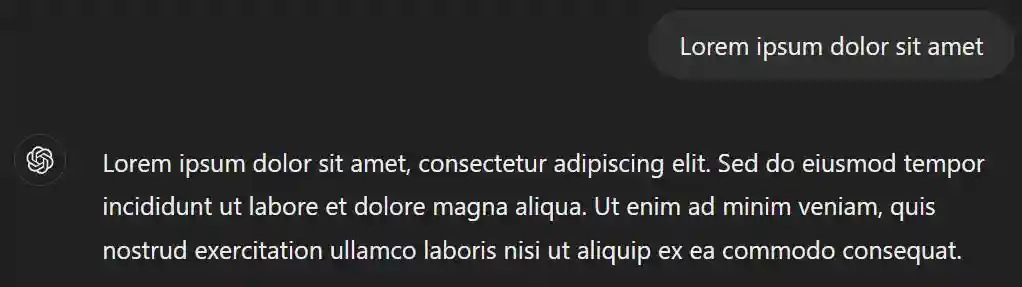
图12.如果未指定任务,ChatGPT仅会继续输入句子

图13.分配特定任务如何导致模型做出不同响应的示例
以自然语言形式提供任务的想法可以通过以自监督的方式用大量文本训练模型来实现。为了进行比较,GPT-1用于执行语言建模的数据集是BooksCorpus数据集,其中包含7000多本未出版的书籍,相当于约5GB的文本。同时,用于GPT-2的数据集是WebText,其大小约为40GB。不仅数据集,而且模型本身也更大。GPT-2论文的作者创建了四个模型变体,每个模型都有不同的配置,如下图14所示。第一行中的模型与我们刚刚实现的GPT-1论文相同,而最后一行中被识别为GPT-2的模型。在这里我们可以看到,就参数数量而言,GPT-2大约是GPT-1的13倍。基于有关数据集和模型大小的这些信息,我们绝对可以预期GPT-2的表现将远远优于其前身。

图14.GPT-2论文中提出的四种模型变体
重要的是要知道,如果我们要实际创建模型,N_LAYERS和D_MODEL并不是我们需要更改的唯一参数。下面的代码块显示了GPT-2的完整参数配置。
好吧,我认为我不需要进一步解释上述代码,因为它与GPT-1的解码器基本相同,只是这里我们将层规范化块放在不同的位置。所以,现在我们将直接跳到测试代码。请参阅下面的代码块16。
Codeblock16outputoriginalresidual:([1,1024,1600])afternormalization:([1,1024,1600])afterattention:([1,1024,1600])afterdropout:([1,1024,1600])afteraddition:([1,1024,1600])xresidual:([1,1024,1600])afternormalization:([1,1024,1600])afterfeedforward:([1,1024,1600])afterdropout:([1,1024,1600])afteraddition:([1,1024,1600])GPT-2实现:带输入和文本预测的解码器
虽然GPT-2中使用的解码器与GPT-1中使用的解码器不同,但其他组件,即位置编码和前瞻掩码,保持不变。因此,我们可以重复使用它们。用于连接这两个组件的代码大致相同,但在下面的Codeblock17中仍有一些复杂的细节需要注意。首先,我们在这里初始化第17行的另一个层规范化(2)。这样做主要是因为在GPT-2中,我们在解码器之外放置了另一个层规范块,而这在GPT-1中以前并不存在(参见图15)。其次,没有必要像我们在类中所做的那样存储原始解码器输出GPT1()(在第18行Codeblock17classGPT23():def__init__(self):super().__init__()_embedding=(num_embeddings=VOCAB_SIZE,embedding_dim=D_MODEL)_encoding=PositionalEncoding()=([DecoderGPT23()for_inrange(N_LAYERS)])_final=(D_MODEL){i}\t:{}")x=_final(x)Codeblock18gpt2=GPT23()x=(0,VOCAB_SIZE,(BATCH_SIZE,SEQ_LENGTH))x=gpt2(x)
0:([1,1024,1600])afterdecoder2:([1,1024,1600])afterdecoder44:([1,1024,1600])afterdecoder46:([1,1024,1600])afterdecoderCodeblock19count_parameters(gpt2)
Codeblock20BATCH_SIZE=1SEQ_LENGTH=2048VOCAB_SIZE=50257D_MODEL=12288NUM_HEADS=96HIDDEN_DIM=D_MODEL*4N_LAYERS=96DROP_PROB=0.1
由于上述变量已更新,我们可以简单地运行以下代码块来初始化GPT-3模型((2))。
(1)x=(0,VOCAB_SIZE,(BATCH_SIZE,SEQ_LENGTH))x=gpt3(x)#(2)
不幸的是,由于内存有限,我无法运行上述代码。我甚至尝试在内存为30GB的KaggleNotebook上运行它,但内存不足错误仍然存在。因此,对于这个,我无法向您显示模型初始化时创建的参数数量。但是,论文中提到GPT-3包含大约1750亿个参数,这基本上意味着它比GPT-2大100多倍,所以现在就可以理解为什么它只能在非常大且功能强大的机器上运行。查看下图以了解GPT版本之间的差异。
图16.不同GPT版本的比较
结束这就是关于不同GPT版本(尤其是GPT-1、GPT-2和GPT-3)的理论和实现的所有内容。






- 同类文章























- 友情链接
-